Sistema de atendimento com múltiplos agentes de IA usando PydanticAI
Sistema de atendimento ao cliente que usa múltiplos agentes de IA especializados para classificar intenções, consultar dados reais e responder com contexto.
Sistemas de atendimento tradicionais têm dois problemas: 1. Um único modelo para tudo: um LLM genérico tenta responder perguntas financeiras, técnicas e de vendas... e geralmente bem em nenhuma delas. 2. Sem acesso a dados reais: o modelo responde com informações genéricas e não consegue dizer "seu pedido #P-4521 está em trânsito". Este projeto demonstra uma alternativa: múltiplos agentes especializados, cada um com acesso às ferramentas e dados relevantes para seu domínio, coordenados por um orquestrador que toma a decisão de roteamento.
Como construí um sistema de atendimento com múltiplos agentes de IA
Por Gleisson Bispo — gleisson.bispo@outlook.com
Quando comecei a estudar IA aplicada com Python, a primeira pergunta que me fiz foi: como você usa LLMs em sistemas reais, onde os dados ficam no banco de dados da empresa, e não no contexto do modelo?
Este projeto é a minha resposta prática para essa pergunta.
O que é este projeto
É um sistema de atendimento ao cliente onde múltiplos agentes de IA trabalham em conjunto: um orquestrador que entende a intenção do cliente e três especialistas que têm acesso a dados reais: pedidos, faturas, produtos.. e uma base de conhecimento com busca semântica.
O cliente digita uma mensagem. O sistema classifica se é um problema técnico,financeiro ou de vendas, delega para o agente certo, que consulta o banco dedados, e responde com informações reais sobre aquele cliente específico.
Tudo isso acontece em tempo real, via WebSocket, com resposta streamada como nos produtos comerciais de IA.
Demo
O problema que eu queria resolver (tecnicamente)
Quando você usa um LLM com llm.chat("minha pergunta"), o modelo responde com o que aprendeu no treinamento ou seja informações genéricas, sem acesso aos dados da sua empresa.
Para sistemas de atendimento reais, você precisa que a IA consiga:
"Seu pedido #P-4521 está em trânsito desde ontem"
"Sua fatura de R$ 350,00 vence em 3 dias"
"O notebook que você viu custa R$ 4.200 e temos 3 em estoque"
Isso requer integrar o LLM com bancos de dados reais, é o que chamamos de tool use ou function calling: o modelo decide quando precisa de uma informação e chama uma função Python para buscá-la.
Por que múltiplos agentes?
A primeira versão que eu imaginei era um único agente que respondia tudo. Mas rapidamente percebi os problemas:
Contexto enorme: um único system prompt precisaria explicar como lidar com problemas técnicos, financeiros e de vendas.O prompt ficaria enorme e o modelo ficaria confuso;
Acesso excessivo: por que um agente de vendas precisa ter acesso ao histórico de faturas? O princípio de menor privilégio existe em IA também;
Manutenção difícil: melhorar o comportamento financeiro quebraria o comportamento técnico se estivessem no mesmo prompt.
A solução foi o padrão Orquestrador + Especialistas:
Mensagem do cliente
│
▼
Orquestrador ──── "Isso é sobre fatura" ────► Agente Financeiro
│
├── consulta banco
└── retorna resposta
O orquestrador não responde diretamente: sua única função é classificar e delegar. Cada especialista só conhece seu domínio.
As tecnologias e por que as escolhi
PydanticAI - O framework de agentes
Eu conhecia LangChain e LlamaIndex, mas fui pesquisar alternativas mais recentes. O PydanticAI me chamou atenção porque ele é schema-first: você define o formato da resposta como um modelo Pydantic e o framework garante que o LLM vai retornar exatamente aquele formato ou vai tentar de novo automaticamente.
Na prática, isso significa que meu código nunca recebe um JSON malformado do LLM. Cada agente retorna um RespostaAgente com campos garantidos:
class RespostaAgente(BaseModel):
mensagem: str # o que o agente diz
sentimento_cliente: Literal[...] # positivo/neutro/negativo/frustrado
precisa_escalar_humano: bool # precisa de atendente humano?
tags: list[str] # tags para análise posteriorclass RespostaAgente(BaseModel):
mensagem: str # o que o agente diz
sentimento_cliente: Literal[...] # positivo/neutro/negativo/frustrado
precisa_escalar_humano: bool # precisa de atendente humano?
tags: list[str] # tags para análise posteriorpgvector - Busca semântica dentro do PostgreSQL
Para o módulo RAG (busca em base de conhecimento), a opção óbvia seria um banco de vetores dedicado como Pinecone. Mas eu me fiz uma pergunta: por que adicionar um serviço a mais se o PostgreSQL já faz isso?
A extensão pgvector adiciona um tipo vector(1536) ao PostgreSQL e suporte a busca por similaridade cosine:
SELECT titulo, conteudo
FROM artigos_conhecimento
ORDER BY embedding <=> $1 -- operador de distância cosine
LIMIT 3;SELECT titulo, conteudo
FROM artigos_conhecimento
ORDER BY embedding <=> $1 -- operador de distância cosine
LIMIT 3;Resultado: o agente técnico busca artigos relevantes com similaridade semântica direto no banco relacional, sem serviço externo.
Redis - sessões e histórico de conversa
O Redis armazena duas coisas:
A sessão ativa de cada cliente (com TTL de 1 hora renovável)
O histórico de conversa (últimas 20 trocas pergunta-resposta)
Por que Redis e não PostgreSQL para isso? Porque são dados de alta frequência e vida curta: lidos e escritos em cada mensagem, e irrelevantes depois de 1 hora. O Redis tem estruturas de dados nativas para isso RPUSH, LTRIM para manter só as últimas N mensagens) e TTL automático por chave.
FastAPI + WebSocket
A resposta do LLM chega progressivamente (token por token). Para criar o efeito de "digitação" da IA, o backend envia cada chunk conforme recebe via WebSocket, o usuário vê a resposta sendo construída em tempo real.
Logfire - Observabilidade
Logfire é a ferramenta de observabilidade da equipe do Pydantic. A parte mais interessante é a auto-instrumentação: com 4 linhas de código, você tem visibilidade completa de:
Cada query SQL com tempo de execução;
Cada comando Redis;
Cada request HTTP com status e latência;
Cada chamada ao LLM com prompt e resposta;
Tudo isso no dashboard do Logfire sem adicionar nenhum código nas funções de negócio.
Algumas coisas que este projeto me ensinou
Tool use é o que transforma LLMs de chatbots em sistemas úteis. O modelo decide quando precisa de dados reais e chama as funções para buscá-los;
Structured output (schema Pydantic como output do agente) é fundamental para integrar LLMs com código Python.. você não quer fazer parsing de texto livre em produção;
Múltiplos agentes especializados produzem resultados melhores que um único agente genérico, mas têm custo de latência (duas chamadas ao LLM).
asynccontextmanagerpara gerenciar ciclo de vida de recursos (banco, Redis);Como o
lifespando FastAPI garante que recursos são criados e destruídos corretamente no startup/shutdown;A diferença entre datetime naive e aware.. e por que isso importa quando você mistura dados de fontes diferentes
Como
${VAR:-default}no docker-compose permite configuração flexível sem expor credenciais;pip install -e .faz sentido em desenvolvimento local mas não em containers;Healthchecks garantem a ordem de inicialização dos serviços;
Information disclosure, erros internos não devem vazar para o cliente, Log completo no servidor, mensagem genérica para o usuário;
Prompt injection, guardrails de regex para detectar tentativas de manipular o sistema
O que o sistema sabe fazer hoje
Para demonstrar, suba o projeto e use o cliente_001 no Streamlit. Experimente:
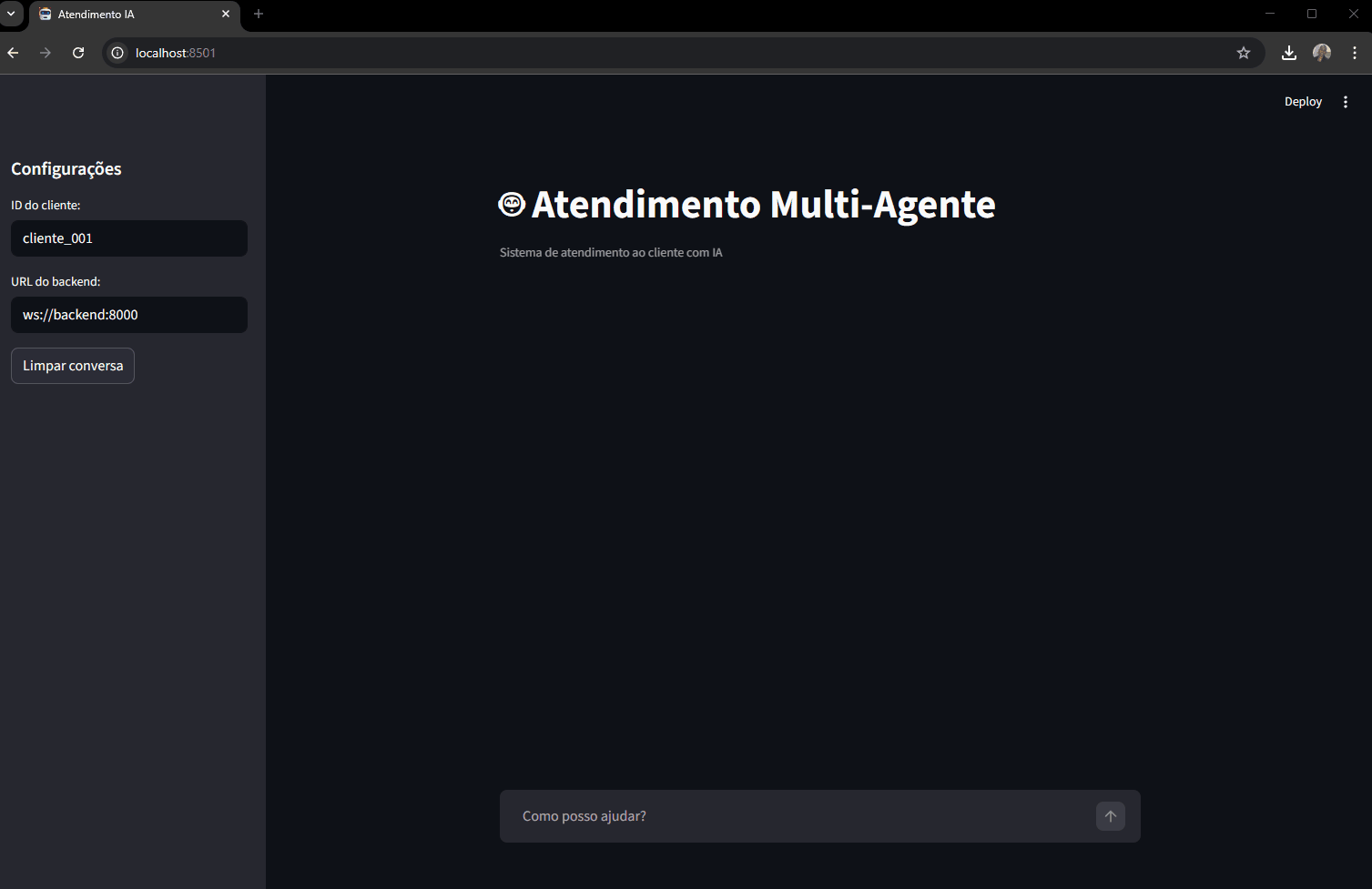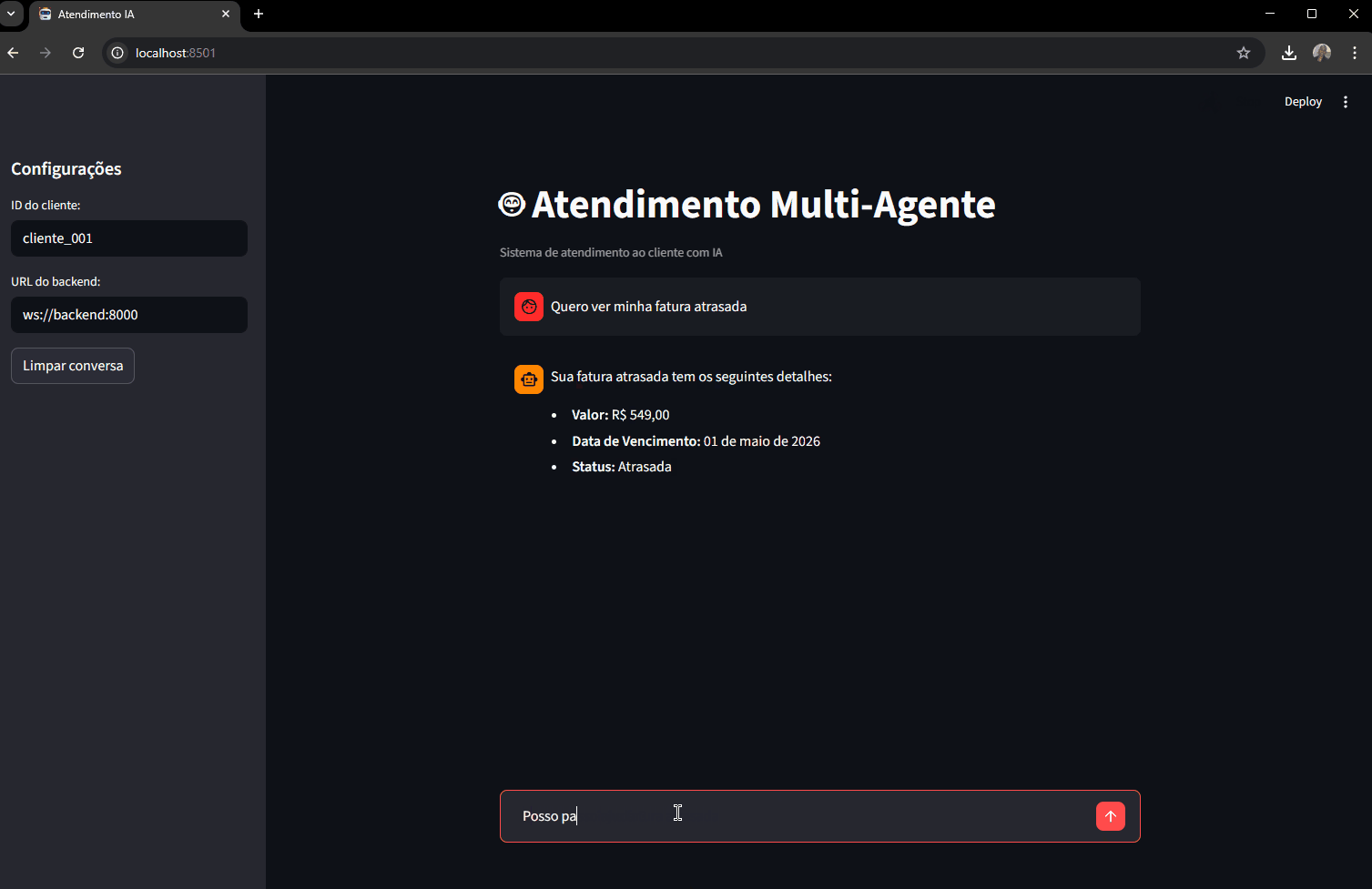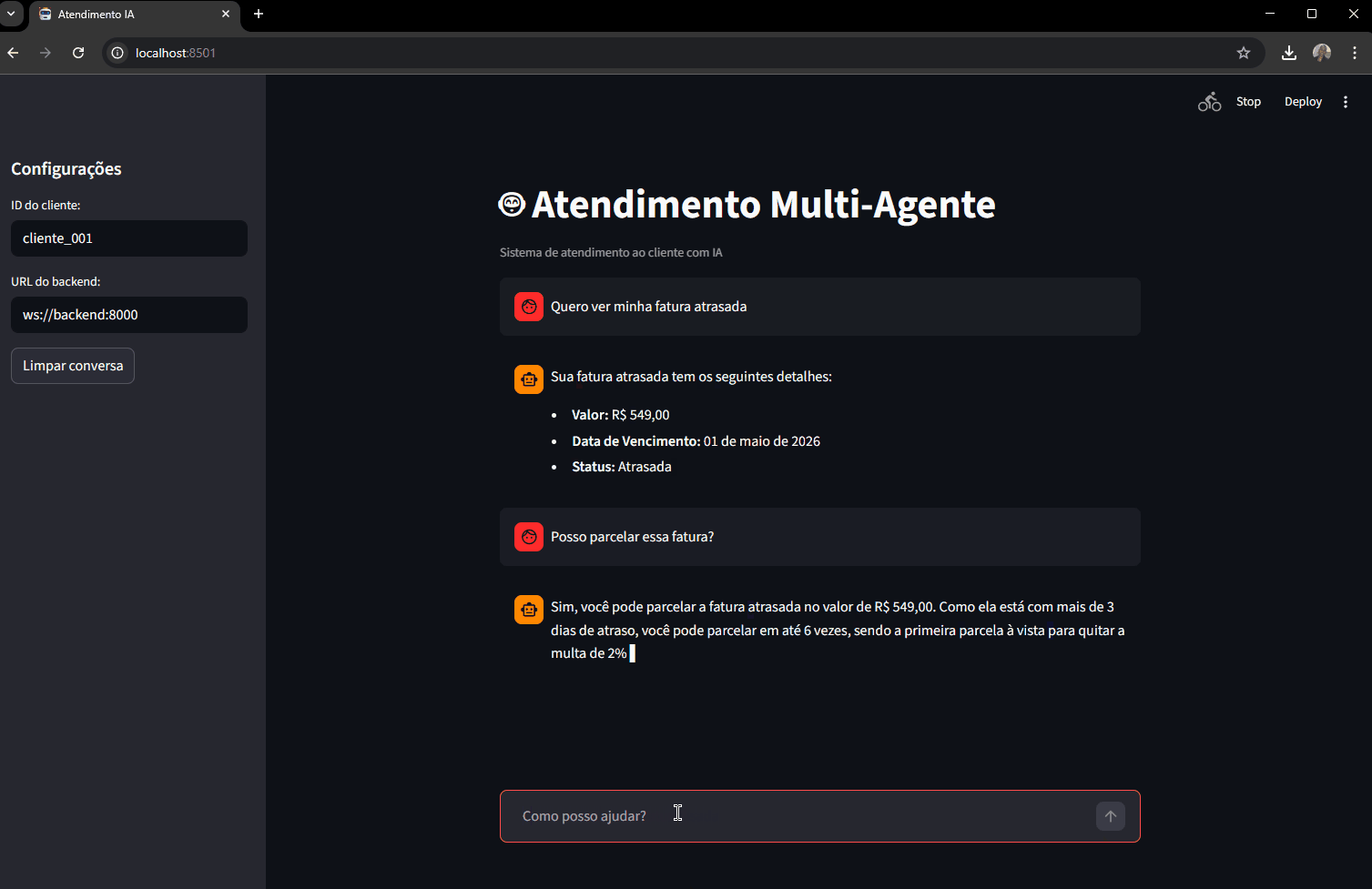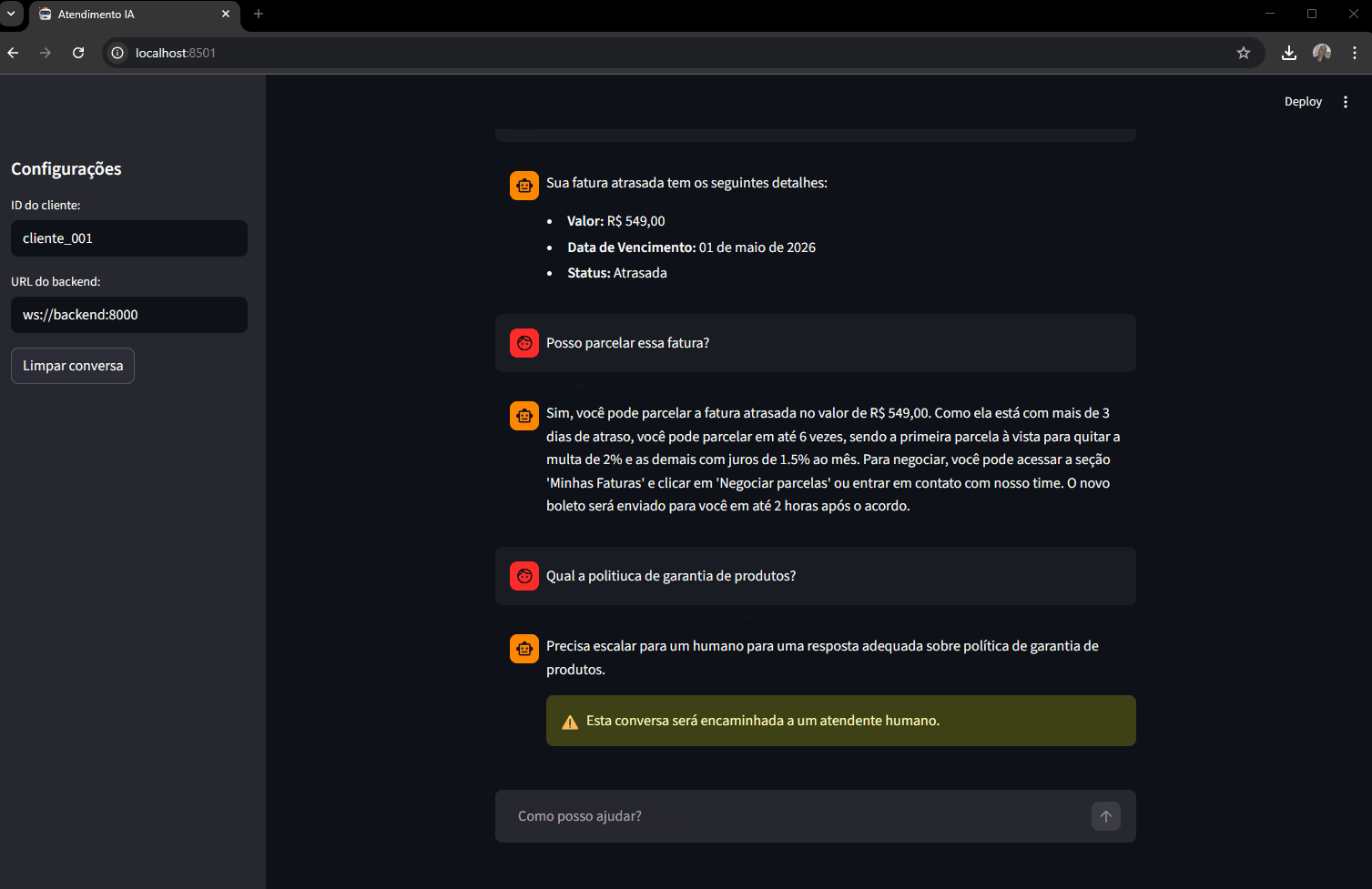
Teste de contexto de conversa:
"Quero ver minha fatura atrasada"
"Posso parcelar ela?"
"Como funciona o parcelamento?"
O agente financeiro vai consultar as faturas reais do cliente, encontrar a FAT-003 atrasada, e na segunda mensagem vai saber a qual fatura você se refere (porque tem acesso ao histórico das últimas mensagens).
Teste de RAG:
"Qual é a política de garantia dos produtos?"
"Como faço para devolver um notebook com defeito?"
O agente de vendas vai buscar o artigo "Garantia dos produtos" na base de conhecimento via busca semântica (e responder com a política real cadastrada), não com informações genéricas do LLM.
Rodando o projeto
git clone https://github.com/gleissonbispo/pydanticai-mult-agentes
cd pydanticai-mult-agentes
cp .env.example .env
# edite .env com sua OPENAI_API_KEY
docker-compose up --buildgit clone https://github.com/gleissonbispo/pydanticai-mult-agentes
cd pydanticai-mult-agentes
cp .env.example .env
# edite .env com sua OPENAI_API_KEY
docker-compose up --buildAcesse http://localhost:8501 e comece a conversar.
Estrutura resumida
backend/app/
├── agents/ # Orquestrador + 3 especialistas (PydanticAI)
├── models/ # SQLAlchemy ORM + Pydantic schemas
├── routes/ # WebSocket handler
├── services/ # Database pool + SessionService (Redis)
├── tools/ # Queries ao banco (usadas pelos agentes como tools)
├── rag/ # Embeddings + busca por similaridade (pgvector)
└── guardrails/ # Validação de input e detecção de prompt injection
⚠️ Importante: Este projeto foi construído como exercício de aprendizado e portfólio. Não é código de produção é um demonstrador de conceitos e arquitetura.